NOTAS WEB

Creación de API Rest: Guía de Buenas Prácticas

Guía completa de buenas prácticas para construir APIs RESTful
Crear una API RESTful bien diseñada es crucial para garantizar que sea fácil de mantener, segura y escalable a largo plazo. Al principio, puede que caigas en la tentación de condensar todo en un solo controlador, como me pasó a mí. Sin embargo, con el tiempo, aprenderás a separar responsabilidades para que cada parte de tu API haga exactamente lo que debe hacer. En esta guía, te comparto las mejores prácticas que he ido adquiriendo con el tiempo, junto a consejos de los expertos.
1. Arquitectura y diseño de recursos
Una buena API REST debe ser intuitiva y fácil de entender. Aquí van algunos puntos clave:
- URI bien diseñados: Cada recurso debe tener su propia URI clara y basada en sustantivos en plural. Por ejemplo, si estás creando un recurso de usuarios, tu endpoint debería ser
/usuarios, no/obtenerUsuarios. - Evitar verbos en los endpoints: Los métodos HTTP ya nos dan una idea de lo que está haciendo la solicitud. Así que en lugar de
/crearUsuario, utiliza el métodoPOSTen el recurso/usuarios. - Jerarquía limitada: Si tienes relaciones entre recursos (como usuarios y publicaciones), evita anidar más de dos niveles. Por ejemplo, usa
/usuarios/123/publicacionesen lugar de algo como/usuarios/123/publicaciones/456/comentarios.
2. Uso adecuado de métodos HTTP y manejo de errores
Cuando empecé, solía tener problemas por mi falta de experiencia devolviendo códigos incorrectos o usar métodos inadecuados, entre otros errores. Por ejemplo, usar PATCH, para cualquier tipo de actualización, ya fuera parcial o total. O para todas las excepciones devolver un código 400. Lo que hacía la API más compleja de lo necesario, y generaba dudas para quien la usaba. Afortunadamente, hoy en día sigo estas reglas simples, que me ayudan a crear endpoints bien estructurados:
- GET para leer datos: Se usa para recuperar recursos.
- POST para crear: Utilízalo para agregar un nuevo recurso, como un nuevo usuario.
- PUT o PATCH para actualizar: PUT reemplaza completamente un recurso, mientras que PATCH lo actualiza parcialmente.
- DELETE para eliminar un recurso.
Además, los códigos de estado HTTP son esenciales para una buena comunicación. Asegúrate de devolver el código correcto:
200 OK: Cuando todo funciona correctamente.400 Bad Request: Si hay un error en la solicitud del cliente, como datos mal formateados.401 Unauthorized: El usuario no está autenticado.403 Forbidden: El usuario está autenticado, pero no tiene los permisos necesarios para realizar la acción.404 Not Found: El recurso solicitado no existe o no está disponible.409 Conflict: Se usa cuando hay un conflicto con el estado actual del recurso, por ejemplo, cuando se intenta crear un recurso que ya existe.422 Unprocessable Entity: Indica que el servidor comprende la solicitud, pero no puede procesarla debido a problemas de validación, como un formato incorrecto en los datos enviados.500 Internal Server Error: Algo falla en el servidor, indicando un problema inesperado en el procesamiento de la solicitud.
3. Seguridad: Protege tu API
Uno de los errores más comunes al empezar es subestimar la importancia de la seguridad. Asegúrate de implementar:
- OAuth 2.0 o JWT: Estos mecanismos son clave para autenticar a los usuarios.
- HTTPS: Protege todas las comunicaciones entre tu cliente y servidor, encriptando los datos.
- Validación de entrada: Nunca confíes en los datos que recibes del usuario sin validarlos. Esto puede prevenir ataques como inyecciones SQL o XSS.
- CORS: Configura correctamente CORS para que solo ciertos dominios puedan acceder a tu API.
4. Optimización y rendimiento
Una API lenta puede ser frustrante para los usuarios. Aquí tienes algunos consejos para mejorar su rendimiento:
- Caché: Implementa caché donde sea posible para reducir el tiempo de respuesta.
- Compresión: Utiliza la compresión (como gzip) para disminuir el tamaño de los datos que viajan entre el cliente y el servidor.
- Paginación: Si tu API devuelve grandes cantidades de datos (como una lista de usuarios), usa paginación para no sobrecargar el sistema.
- Rate Limiting: Limita el número de solicitudes que un usuario puede hacer por minuto para evitar abusos y mejorar la estabilidad de tu API.
5. Documentación y versionado
Nada frustra más a un desarrollador que una API mal documentada. Usa herramientas como OpenAPI/Swagger para crear documentación interactiva que sea fácil de seguir.
- Versionado: Siempre incluye versiones en tu API, como
/api/v1/usuarios, para que puedas hacer cambios importantes sin afectar a todos tus usuarios.
6. Diseño de endpoints coherentes
Un buen diseño de endpoints es clave para mantener la API organizada:
- Nombres en plural: Utiliza siempre el plural para colecciones, por ejemplo,
/productosen lugar de/producto. - Filtrado y paginación: Permite a los usuarios filtrar y ordenar los datos devueltos, así como paginar grandes conjuntos de datos.
7. Pruebas y monitoreo
Finalmente, asegúrate de probar todo antes de lanzar. Haz pruebas unitarias, de integración, y también de seguridad. Una vez en producción, monitorea la salud y el rendimiento de la API para asegurarte de que todo sigue funcionando como debería.
8. Separación de responsabilidades: El flujo correcto e incorrecto en una API
Uno de los aspectos más importantes que he aprendido con el tiempo es la importancia de separar correctamente las responsabilidades dentro de una API. Al principio, es fácil caer en la trampa de concentrar toda la lógica de validación, control de flujo y acceso a datos en un solo lugar, generalmente en el controlador. Aunque esto puede parecer eficiente al principio, rápidamente se convierte en un problema a medida que la API crece en complejidad y responsabilidades.
Flujo incorrecto: Todo en el controlador
En la primera imagen, podemos ver el flujo incorrecto, donde todo (validación de datos, lógica de negocio y acceso a la base de datos) está gestionado directamente desde el controlador. Este tipo de estructura centralizada puede ser problemática por varias razones:
- Dificultad de mantenimiento: A medida que el proyecto crece, este enfoque se vuelve ineficiente. Cada vez que quieras modificar una parte del proceso, como la validación o la interacción con la base de datos, tendrás que hacerlo dentro del controlador, lo que añade complejidad y aumenta el riesgo de introducir errores.
- Código acoplado: Los cambios en la lógica de negocio o en el acceso a los datos afectarán al controlador directamente, haciendo que el código sea menos flexible y más difícil de escalar.

(Descripción visual: Todo el proceso de validación, lógica de negocio y acceso a datos está contenido en el controlador, creando un acoplamiento excesivo.)
Flujo correcto: Separación de responsabilidades
En la segunda imagen, puedes ver el flujo correcto para el diseño de una API bien estructurada. Aquí, cada parte del proceso tiene su responsabilidad claramente separada:
- Validación de entrada: Se realiza antes de que los datos lleguen al controlador. Esto asegura que solo datos válidos pasen al siguiente nivel.
- Controlador: Su única responsabilidad es recibir la solicitud, delegar el trabajo y enviar la respuesta. El controlador no contiene lógica de negocio.
- Servicio de lógica de negocio: Aquí es donde reside la lógica de la aplicación. Se encarga de procesar las reglas de negocio, manteniendo el controlador ligero.
- Acceso a recursos: El servicio interactúa con recursos externos como bases de datos o APIs de terceros. Esto permite que el controlador se mantenga desacoplado de la implementación específica de cómo se obtienen los datos.
Este enfoque tiene varios beneficios:
- Fácil de mantener: Si necesitas cambiar la validación o cómo interactúas con la base de datos, puedes hacerlo en el lugar adecuado sin afectar al controlador o la lógica de negocio.
- Escalabilidad: Separar las responsabilidades facilita escalar y agregar nuevas características sin comprometer la estabilidad del sistema.
- Reusabilidad: Las funciones como la validación o el acceso a datos pueden reutilizarse en otros controladores o partes de la aplicación sin duplicar código.
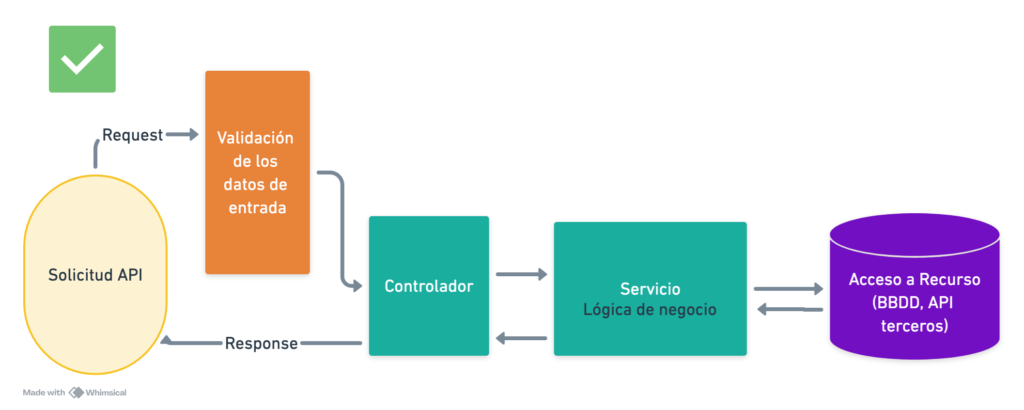
(Descripción visual: Las responsabilidades están claramente separadas en validación de datos, controlador, servicio de lógica de negocio y acceso a la base de datos.)
Conclusión sobre la separación de responsabilidades
Aplicar esta separación estructurada permite crear APIs más robustas, mantenibles y escalables. Cuando comencé a desarrollar APIs, cometí el error de agrupar todo en el controlador. Sin embargo, con el tiempo he aprendido que al desacoplar responsabilidades, no solo facilitas el mantenimiento, sino que también mejoras la eficiencia y la capacidad de respuesta de la API. Además, este enfoque sigue el principio «Single Responsibility», que es clave en el diseño de software limpio. A continuación te dejo un enlace de un artículo del blog, dónde aplicamos los principios SOLID en la creación de un APIRest, enlace
Conclusión
Implementar estas mejores prácticas te permitirá construir una API RESTful segura, eficiente y mantenible. No olvides la importancia de separar responsabilidades dentro de tu código para que sea más fácil de gestionar a largo plazo, una lección que aprendí a lo largo de los años.

Desarrollador de software con más de 7 años de experiencia, especializado en desarrollo web y backend. Con habilidades demostradas en PHP, Laravel, Symfony, y una amplia gama de tecnologías modernas. Apasionado por el diseño y desarrollo de software.


